What's New in Claude 3.5

Summary
Claude 3.5 by Anthropic revolutionizes AI capabilities with tailored models: Haiku for speed, Sonnet for complex tasks, and Opus for in-depth analysis. Key features include advanced reasoning, multilingual processing, and the groundbreaking "computer use" feature for automating workflows. With enterprise-grade compliance, seamless integration via AWS and GCP, and cost-efficient pricing, Claude 3.5 sets a new standard in AI performance.
Key insights:
Model Specialization: Claude 3.5 offers Haiku for speed-centric tasks, Sonnet for precision workflows, and Opus for analytical needs.
Innovative Feature: The "computer use" feature enables Claude to interact with software, automating workflows and multitasking.
Advanced Reasoning: Excels in Chain-of-Thought and Zero-Shot problem-solving for complex tasks.
Multilingual Capabilities: Supports diverse languages and handles multilingual mathematical problem-solving.
Enterprise Compliance: Fully compliant with SOC 2 Type II and HIPAA standards, suitable for high-stakes business scenarios.
Cost Efficiency: Pricing starts at $1 per million tokens with options like prompt caching and message batching for cost savings.
Wide Availability: Accessible via Anthropic API, AWS Bedrock, and Google Cloud’s Vertex AI for seamless integration.
Introduction
Claude 3.5 represents an advancement in AI technology that pushes the field's boundaries with its innovative capabilities. It is designed to meet the needs of both; individuals and organizations. With capabilities that surpass traditional AI boundaries, Claude 3.5 provides advanced reasoning, image analysis, multilingual processing, and also code generation. This model, made by Anthropic, includes the lightweight “Haiku” for fast, simple tasks, “Sonnet” for high-throughput needs, and “Opus” for in-depth analysis. Claude meets the demands of enterprise-level applications with its incredible accessibility (via AWS and GCP) and with strict compliance options such as SOC 2 Type II and HIPAA.
Claude 3.5 integrates the best jailbreak resistance and misuse prevention to make it highly reliable for high-stakes business scenarios. This release also introduces Claude’s groundbreaking “computer use” capability, which further improves seamless resource management and multitasking. Claude 3.5 tackles complex projects with high accuracy and minimal errors, setting new standards for performance in the AI industry.
Latest Updates to Claude 3.5
The Claude 3.5 series by Anthropic introduced new advancements tailored to diverse needs. The recent updates to Haiku (from version 3 to 3.5) and Sonnet (Performance Boosts to Sonnet 3.5) and the introduction of computer use have further solidified Anthropic’s position in the AI market. Claude 3.5 Haiku and Claude 3.5 Sonnet have been optimized for specific real-world tasks. These models have seen improvements in speed, complexity management, and intelligent interaction. With these updates, both Haiku and Sonnet redefine standards in their areas. Below, we will dive into both models.
1. Claude 3.5 Haiku
Claude 3.5 Haiku is the latest in speed-centric AI. It retains the fast response rates from its predecessor, but now has significant enhancements in a broad range of skill sets. Haiku has been built for applications that rely on low latency and surpasses Claude 3 Opus, the previous largest model on several intelligence benchmarks. This model is available on Amazon Bedrock, Google Cloud’s Vertex AI, and Anthropic’s API. It now provides improved instruction-following abilities and enhanced tool use. All of these make it a good choice for real-time, user-facing applications.
The updated Claude 3.5 Haiku is particularly beneficial for the following use cases:

This iteration brings expanded utility and offers increased speed for critical applications. The capabilities allow businesses to create responsive, scalable solutions starting at $1 per million input tokens and $5 per million output tokens.
2. Claude 3.5 Sonnet
Claude 3.5 Sonnet represents Anthropic’s most advanced AI for high-stakes, detailed-oriented tasks. It now has support for handling complex workflows and is designed to excel in software engineering, data analysis, and computer use. It has been made available via Anthropic’s API, Amazon Bedrock, and Google Cloud’s Vertex AI. Sonnet supports a range of tasks with new, human-like precision in computer interactions. Priced at $3 per million input tokens and $15 per million output tokens, Sonnet also has cost-saving options (like prompt caching and Message Batches) that make it a good choice for various businesses that might rely on data-driven decision-making.
The updated Claude 3.5 Sonnet is particularly beneficial for the use cases below:
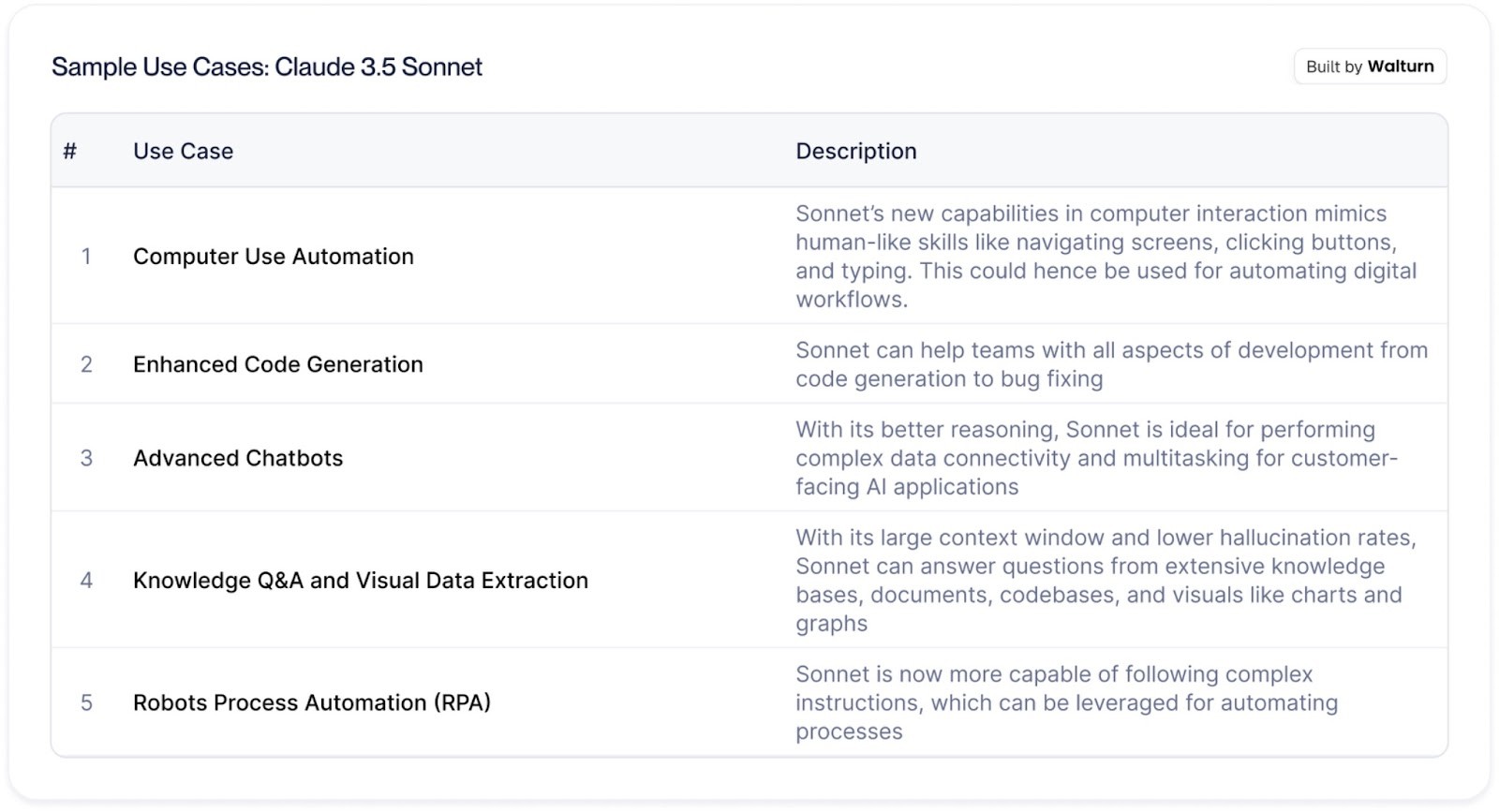
Anthropic aims to deliver a model that is not only reliable and safe like Haiku, but also more capable of handling sophisticated tasks. This led to the enhanced interaction features that make Sonnet a solid choice for applications that require precise, computer-like usage and decision-making.
3. Computer Use
Computer Use is a feature that allows Claude 3.5 Sonnet to perform tasks by looking at a screen, moving a cursor, clicking buttons, and typing text; it gives Claude the ability to interact with computers the way an ordinary human would. The feature is currently experimental and has been made available in public beta. It can be used to automate workflows and complete multistep tasks directly through the standard third-party software that a business might be using.
Several tools, including “Replit”, “Canva”, and “The Browser Company” are exploring its potential. For example, Replit is using “computer use” to develop a feature that evaluates apps during development. These capabilities unlock the automation of complex processes like gathering data in spreadsheets and submitting online forms, with minimal human interaction. Claude’s performance on benchmarks like OSWorld highlights its potential, scoring 14.9% in computer interaction tasks compared to just 7.8% by competing systems.
The technology is still in its infancy and marks a leap forward in the technological landscape. Actions like dragging or scrolling remain challenging, and the folks at Anthropic are actively refining their implementations to further refine these features. It should also be noted that this new feature does have the potential to be misused and that Anthropic has implemented measures to monitor the use of this feature in order to mitigate risks of misuse.
Moreover, Claude is set to redefine how we integrate AI into everyday workflows and hopes to turn labor-intensive processes into seamless, automated solutions. Anthropic invites developers to explore this beta feature and help shape its future.
Benchmark Comparisons
Below is a comparison table between Claude 3.5 Sonnet (new), Claude 3.5 Haiku, LLaMa 3.1 405B, and OpenAI’s o1-preview:
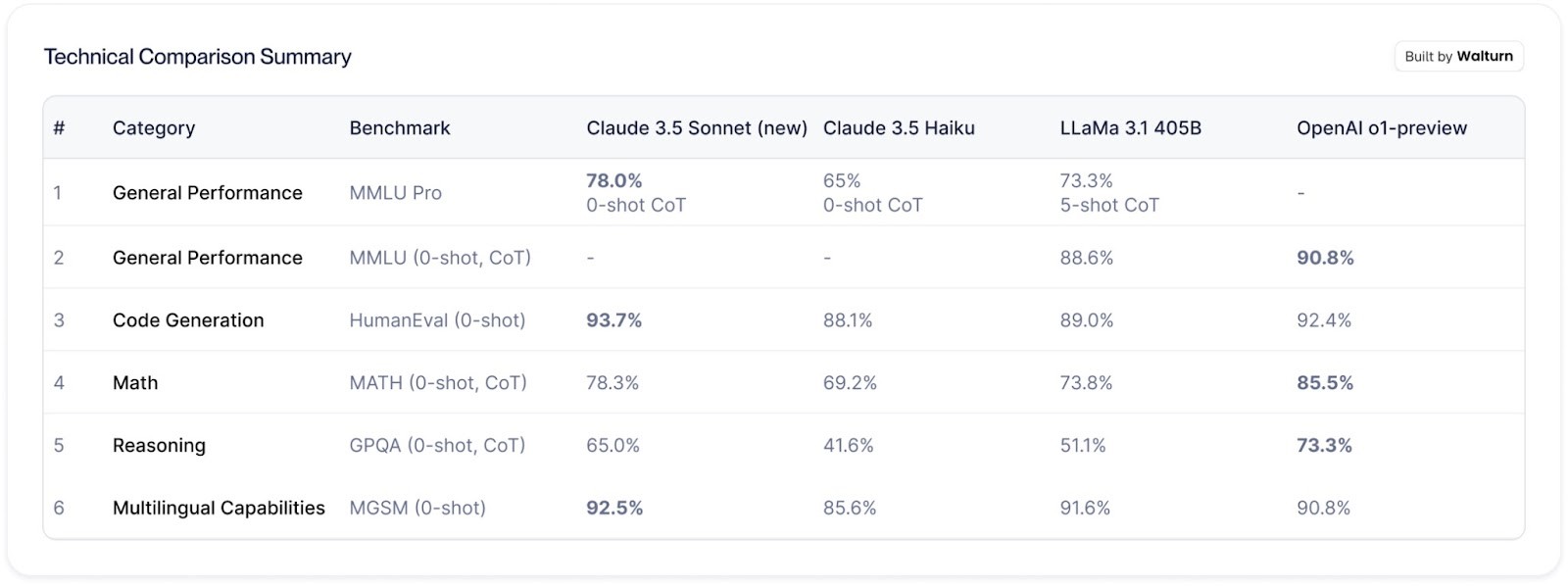
To better understand the benchmarks referenced in the table, here’s a brief explanation of key concepts followed by descriptions of each benchmark:
Chain-of-Thought (CoT): CoT prompting encourages the model to explain its reasoning process step-by-step before arriving at an answer, which often enhances performance on tasks requiring logic or problem-solving.
Zero-Shot (0-shot): In zero-shot evaluation, the model tackles tasks without any prior examples, relying solely on its inherent knowledge and reasoning capabilities.
MMLU: The Massive Multitask Language Understanding (MMLU) benchmark evaluates performance across a range of subjects. It tests the model’s ability to answer questions without prior examples and often benefits from Chain-of-Thought reasoning
MMLU Pro: An advanced version of MMLU, this benchmark increases difficulty by expanding the number of answer choices from four to ten, making random guessing less effective and demanding greater accuracy.
HumanEval: This benchmark measures the model’s ability to generate correct code solutions for various programming tasks without prior examples.
MATH: The Mathematics Aptitude Test of Heuristics (MATH) comprises 12,500 competition-level math problems. This benchmark assesses the model’s problem-solving skills and benefits from Chain-of-Thought reasoning.
GPQA: The Graduate-Level Google-Proof Q&A (GPQA) benchmark tests reasoning on 448 complex multiple-choice questions designed by domain experts. These questions are crafted to be unanswerable through simple web searches, focusing on the model’s critical thinking.
MGSM: This benchmark evaluates the model’s multilingual mathematical problem-solving by presenting 250 math questions from the GSM8K dataset translated into ten different languages.
Conclusion
In conclusion, the recent updates to Claude 3.5 are transformative advancements in AI technology, offering tailored solutions for simple and complex applications. Anthropic aims to meet diverse business needs with Haiku, which focuses on speed, and with Sonnet, which focuses on precision. Another feature introduced is “computer use” which further elevates Claude's functionality. While still in development, the advancements are redefining AI integrations with modern work environments and setting new reliability and AI functionality standards. For further reading on Claude, check out our articles comparing the pre-update version of Claude 3.5 Sonnet to OpenAI’s GPT 4o and o1 models. We also have a guide on prompt engineering for Claude which should be helpful for whatever Claude model you plan on using!
Authors





Leverage Claude 3.5 with Walturn's AI Expertise
Walturn harnesses the power of cutting-edge AI models like Claude 3.5 to drive innovation and efficiency in your business. From seamless integration to ongoing maintenance and monitoring, our team ensures that Claude 3.5 is optimized for your unique use cases. Whether you need advanced reasoning, real-time responsiveness, or sophisticated workflows, Walturn can help you implement and maximize the potential of this transformative technology.
References
Ahmed, Abdullah. “What Is Claude and How Does It Compare to ChatGPT? - Walturn Insight.” Walturn.com, 20 Mar. 2024, www.walturn.com/insights/what-is-claude-and-how-does-it-compare-to-chatgpt.
“Claude.” Www.anthropic.com, www.anthropic.com/claude.
Comparing GPT-4o, LLaMA 3.1, and Claude 3.5 Sonnet - Walturn Insight. www.walturn.com/insights/comparing-gpt-4o-llama-3-1-and-claude-3-5-sonnet.
Comparing OpenAI O1 to Other Top Models - Walturn Insight. www.walturn.com/insights/comparing-openai-o1-to-other-top-models.
“Developing a Computer Use Model.” Anthropic.com, 2024, www.anthropic.com/news/developing-computer-use.
OpenAI. “Learning to Reason With LLMs.” OpenAI, 12 Sept. 2024, openai.com/index/learning-to-reason-with-llms.
Openai/Gsm8k · Datasets at Hugging Face. 17 July 2023, huggingface.co/datasets/openai/gsm8k.











































