A Detailed Comparison Between AI Models Offered by OpenAI

Summary
OpenAI's diverse AI models address various tech needs: ChatGPT excels in conversational AI, Codex automates coding, DALL-E generates images from text, CLIP enhances image-text understanding, Whisper focuses on speech recognition and translation, and Sora, still developing, creates videos from text. Each model showcases OpenAI's commitment to expanding AI capabilities across different domains.
Key insights:
ChatGPT and GPT-4 offer advanced text-based interactions with multimedia functionalities.
Codex facilitates programming tasks and automates code generation.
DALL-E evolves in creating detailed images from textual descriptions, impacting digital art.
CLIP bridges text and image understanding, useful for tasks like reverse image searches.
Whisper delivers robust speech recognition and translation in diverse environments.
Sora experiments with generating realistic video content from text, indicating future possibilities in AI-driven media production.
Introduction
OpenAI has seen substantial growth and attention to its collection of AI models since the launch of ChatGPT in 2022, which was a notable milestone in the world of Natural Language Processing. Since then, OpenAI has expanded on its offerings of AI models including Sora, which was recently revealed. This detailed comparison aims to provide a breakdown of the different models offered by OpenAI in order to provide valuable insights for developers, researchers, and tech enthusiasts.
ChatGPT
Launched in 2022, ChatGPT is a chatbot based on a large language model. It is capable of understanding, responding, and engaging in conversations with humans. Within 5 days of its launch, the service exceeded 1 million users. Currently, ChatGPT has over 180 million users. The base model, offered for free to users upon registration, uses GPT-3.5, which was trained on data up to 2022 and has approximately 175 billion parameters. The inputs from the users are limited to text-form only.
The “plus model”, features GPT-4 and is offered at a price of $20/month. The model was trained on data from up to 2023 with access to bing search for real-time research capabilities. The number of parameters are not publicly available. In addition to this, GPT-4 has an added functionality of accepting and providing images as input/output.
Codex
Launched in 2021, Codex is designed to understand and generate programming code in multiple languages. GitHub Copilot is powered by OpenAI to provide various useful tasks such as completing automatic programming tasks, providing explanations to coding problems, as well as automatically executing programs on the user’s behalf. Codex was trained on a dataset containing code repositories from GitHub in May 2020 - the final dataset, after filtering out automatically generated files and small files, included 159 GB of unique python files.
DALL-E
Launched in 2021, DALL-E is an AI model that can generate images from text descriptions. It quickly grabbed attention for its ability to create complex and detailed images based on a wide range of prompts. DALL-E was trained on a broad range of internet-collected images and text. Its initial version demonstrated the potential of AI in creative fields, leading to the release of DALL-E 2 in April 2022, which improved upon the original's capabilities significantly.
DALL-E 2 introduced a more refined image generation process, offering higher resolution images and more accurate representations of the prompts provided. The service experienced rapid hype among digital artists. OpenAI also introduced DALL-E 3, further enhancing the model's ability to understand and interpret complex prompts, allowing for further improvements in the model.
CLIP
Launched in 2021, CLIP (Contrastive Language–Image Pre-training) is a deep neural network that was trained on a dataset of 400 million image-text pairs, which is different from conventional models that are trained on a single type of input. In addition to this, CLIP was trained on text description in natural language rather than machine-learning compatible format which makes the scalability of the model easier and improves “zero-shot performance” (when the model is tasked to classify an image that did not belong to any label in the training dataset). This allows the model to perform a variety of tasks such as image classification, object detection, and generating textual descriptions from images, allowing it to bridge the gap between images and text. CLIP's unique capability to understand images in the context of textual information makes it a useful tool for applications that require a deep understanding of both visual and textual data such as reverse image search.
WHISPER
Launched in 2022, Whisper is an advanced automatic speech recognition and translation system. Whisper was trained on a dataset consisting of 680,000 hours of audio samples and their transcriptions across different languages, environments, and dialects, allowing it to transcribe audio in difficult environments. The model involves three core components: language identifications, translation of speech to english, and transcription of the audio and achieves results that are competitive to state-of-the art models.
SORA
It is worth mentioning that OpenAI recently revealed another model which further demonstrates creativity of AI. Sora is a text-to-video model that is capable of transforming text prompts into realistic videos with multiple objects and characters. Sample videos from this model continue to come out from the few artists that were given early access to the model. Sora is certainly not a finished product at the moment as it struggles with the physics of complex scenes and sometimes fails to comprehend spatial continuity.
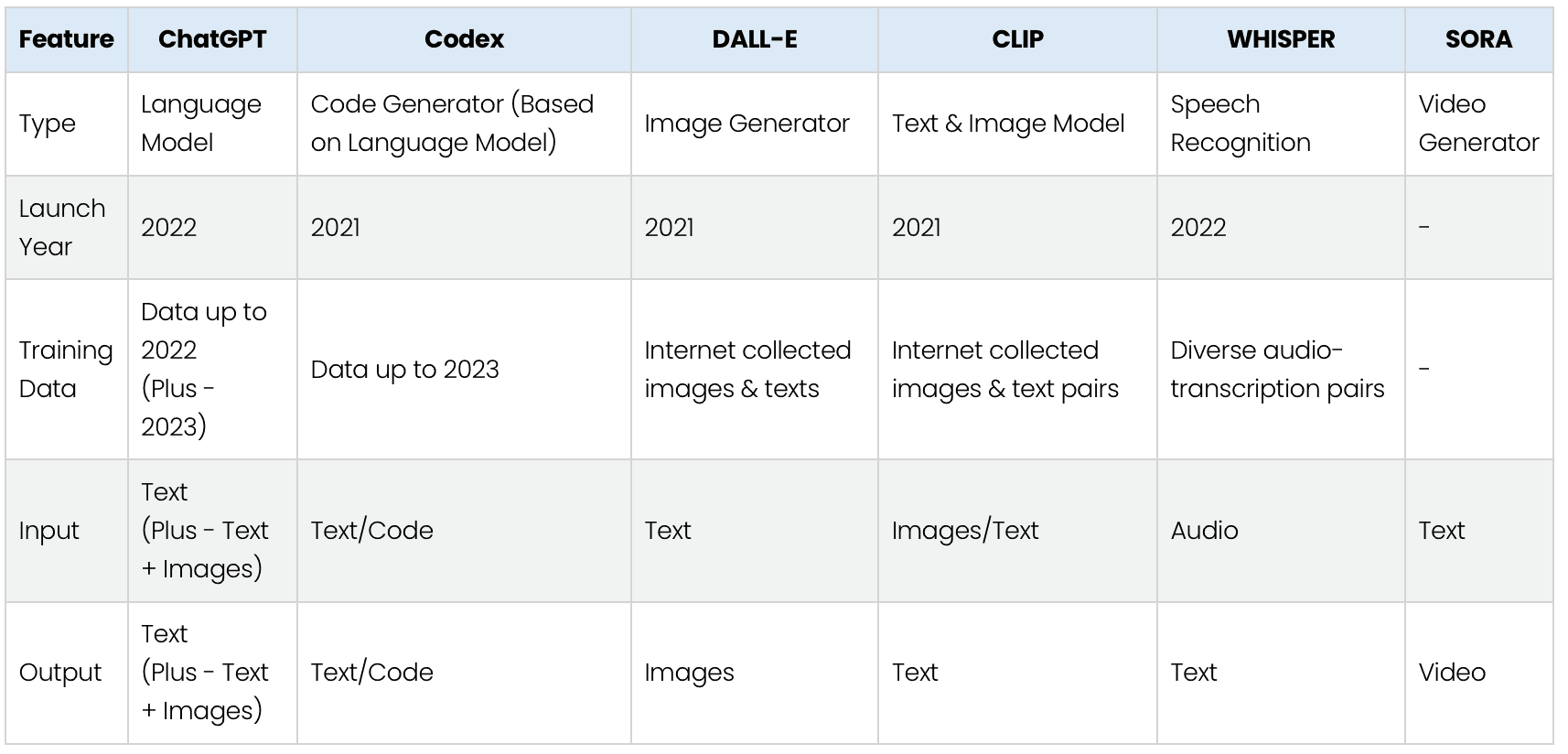
Comparison of all OpenAI Models
Sample Use Cases

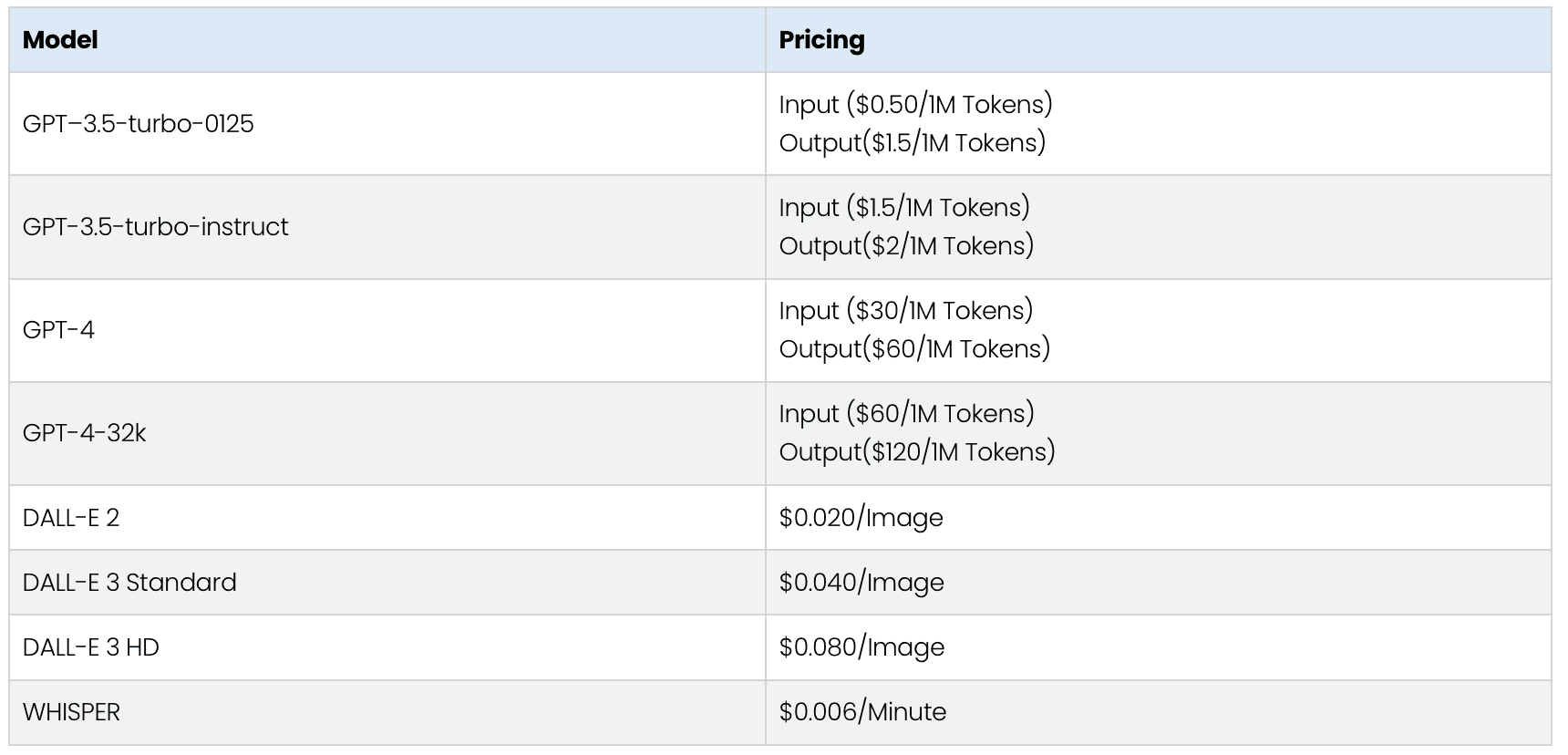
Pricing Overview
Authors



References
https://openai.com/pricing
https://www.demandsage.com/chatgpt-statistics/
Radford, Alec, et al. Learning Transferable Visual Models from Natural Language Supervision.
Radford, Alec, et al.Robust Speech Recognition via Large-Scale Weak Supervision.
Chen, Mark, et al. Evaluating Large Language Models Trained on Code.